Beneath the canvas
Recently a blog post made its rounds on the internet describing how it is possible to speed up plot creation in ggplot2 by first creating a blank canvas and then later adding the plot elements on top of it. The main takeaway plot is reproduced below:

The blog post is in generally well reasoned and I love how it moves from a curious observation to an investigation and ends with a solid recommendation. Alas, I don’t agree with the recommendation (that you should create a canvas for subsequent use). Most of the misunderstanding in the blog post comes from the fact that ggplot2 in many ways seems to be fueled by magic and unicorn blood — what arises when you write ggplot() and hit enter is far from clear. I would like to spend most of the time on this point so I’m just going to get a more general point out of the way first.
Premature optimisation is premature
When looking for ways to optimise your code, one must always ask whether the code needs optimisation in the first place, and then whether the changes made successfully makes a meaningful impact. What the plot above shows is that caching the ggplot() call leads to a statistically significant performance improvement meassured in <10 ms. This means that in order to get a percievable runtime difference, it would be necessary to generate hundreds of plots, or thousands of plots to get a meaningful difference. My own rule of thumb is that you should not give up coding conventions unless there’s a tangible result, and in this case I don’t see any. Does this mean you should never strive for millisecond improvements? No, if you expect your piece of code to be called thousands of times and compounding the effect this would be worthwhile. This is why you sometimes see code where the square root of a variable is saved in a new variable rather than being computed on the fly every time. In this case you should ask yourself whether you mean to generate a 1000 plots with your code in one go, and if so, whether an additional second is really worth it.
There is no spoon canvas
The notion that ggplot() creates a canvas for subsequent calls to add onto is a sensible one, supported by the ggplot2 API where layers are added to the initial plot. Further, if we simply write ggplot() and hits enter we get this:
library(ggplot2)
ggplot()

Which sure looks like a blank canvas. This is all magic and unicorns though - the call to ggplot() doesn’t actually draw or render anything on the device. In order to understand what is going on, let’s have a look at the code underneath it all:
ggplot
#> function(data = NULL, mapping = aes(), ...,
#> environment = parent.frame()) {
#> UseMethod("ggplot")
#> }
#> <environment: namespace:ggplot2>
So, ggplot() is an S3 generic. As it is dispatching on the data argument, and that defaults to NULL I’ll take the wild guess and say we’re using the default method:
ggplot2:::ggplot.default
#> function(data = NULL, mapping = aes(), ...,
#> environment = parent.frame()) {
#> ggplot.data.frame(fortify(data, ...), mapping, environment = environment)
#> }
#> <environment: namespace:ggplot2>
Huh, so even if we’re not passing in a data.frame as data we’re ending up with a call to the data.frame ggplot method (this is actually the reason why you can write your own fortify methods for custom objects and let ggplot2 work with them automatically). Just for completeness let’s have a look at a fortified NULL value:
fortify(NULL)
#> list()
#> attr(,"class")
#> [1] "waiver"
We get a waiver object, which is an internal ggplot2 approach to saying: “I’ve got nothing right now but let’s worry about that later” (grossly simplified).
With that out of the way, let’s dive into ggplot.data.frame():
ggplot2:::ggplot.data.frame
#> function(data, mapping = aes(), ...,
#> environment = parent.frame()) {
#> if (!missing(mapping) && !inherits(mapping, "uneval")) {
#> stop("Mapping should be created with `aes() or `aes_()`.", call. = FALSE)
#> }
#>
#> p <- structure(list(
#> data = data,
#> layers = list(),
#> scales = scales_list(),
#> mapping = mapping,
#> theme = list(),
#> coordinates = coord_cartesian(),
#> facet = facet_null(),
#> plot_env = environment
#> ), class = c("gg", "ggplot"))
#>
#> p$labels <- make_labels(mapping)
#>
#> set_last_plot(p)
#> p
#> }
#> <environment: namespace:ggplot2>
This is actually a pretty simple piece of code. There are some argument checks to make sure the mappings are provided in the correct way, but other than that it is simply constructing a gg object (a ggplot subclass). The set_last_plot() call makes sure that this new plot object is now retrievable with the last_plot() function. In the end it simply returns the new plot object. We can validate this by looking into the return value of ggplot():
str(ggplot())
#> List of 9
#> $ data : list()
#> ..- attr(*, "class")= chr "waiver"
#> $ layers : list()
#> $ scales :Classes 'ScalesList', 'ggproto', 'gg' <ggproto object: Class ScalesList, gg>
#> add: function
#> clone: function
#> find: function
#> get_scales: function
#> has_scale: function
#> input: function
#> n: function
#> non_position_scales: function
#> scales: NULL
#> super: <ggproto object: Class ScalesList, gg>
#> $ mapping : list()
#> $ theme : list()
#> $ coordinates:Classes 'CoordCartesian', 'Coord', 'ggproto', 'gg' <ggproto object: Class CoordCartesian, Coord, gg>
#> aspect: function
#> distance: function
#> expand: TRUE
#> is_linear: function
#> labels: function
#> limits: list
#> modify_scales: function
#> range: function
#> render_axis_h: function
#> render_axis_v: function
#> render_bg: function
#> render_fg: function
#> setup_data: function
#> setup_layout: function
#> setup_panel_params: function
#> setup_params: function
#> transform: function
#> super: <ggproto object: Class CoordCartesian, Coord, gg>
#> $ facet :Classes 'FacetNull', 'Facet', 'ggproto', 'gg' <ggproto object: Class FacetNull, Facet, gg>
#> compute_layout: function
#> draw_back: function
#> draw_front: function
#> draw_labels: function
#> draw_panels: function
#> finish_data: function
#> init_scales: function
#> map_data: function
#> params: list
#> setup_data: function
#> setup_params: function
#> shrink: TRUE
#> train_scales: function
#> vars: function
#> super: <ggproto object: Class FacetNull, Facet, gg>
#> $ plot_env :<environment: R_GlobalEnv>
#> $ labels : list()
#> - attr(*, "class")= chr [1:2] "gg" "ggplot"
We see our waiver data object in the data element. As expected we don’t have any layers, but (perhaps surprising) we do have a coordinate system and a facet specification. These are the defaults getting added to every plot and in effect until overwritten by something else (facet_null() is simply a one-panel plot, cartesian coordinates are a standard coordinate system, so the defaults are sensible). While there’s a default theme in ggplot2 it is not part of the plot object in the same way as the other defaults. The reason for this is that it needs to be possible to change the theme defaults and have these changes applied to all plot objects already in existence. So, instead of carrying the full theme around, a plot object only keeps explicit changes to the theme and then merges these changes into the current default (available with theme_get()) during plotting.
All in all ggplot() simply creates an adorned list ready for adding stuff onto (you might call this a virtual canvas but I think this is stretching it…).
So how come something pops up on your plotting device when you hit enter? (for a fun effect read this while sounding as Carrie from Sex and the City)
This is due to the same reason you get a model summary when hitting enter on a lm() call etc.: The print() method. The print() method is called automatically by R every time a variable is queried and, for a ggplot object, it draws the content of your object on your device. An interesting side-effect of this is that ggplots are only rendered when explicetly print()ed/plot()ed within a loop, as only the last return value in a sequence of calls gets its print method invoked. This also means that the benchmarks in the original blogposts were only measuring plot object creation, and not actual plot rendering, as this is never made explecit in the benchmarked function (A point later emphasized in the original post as well). For fun, let’s see if doing that changes anything:
canv_mt <- ggplot(mtcars, aes(hp, mpg, color = cyl))+
coord_cartesian()
# test speed with mocrobenchmark
test <- microbenchmark::microbenchmark(
without_canvas = plot(ggplot(mtcars, aes(hp, mpg, color = cyl)) +
coord_cartesian() +
geom_point()),
with_canvas = plot(canv_mt +
geom_point()),
times = 100
)
test
#> Unit: milliseconds
#> expr min lq mean median uq max
#> without_canvas 296.3652 324.4996 421.9617 337.3135 379.7957 2306.959
#> with_canvas 304.9903 324.7075 412.8533 334.9704 352.0597 2274.172
#> neval cld
#> 100 a
#> 100 aautoplot(test) +
scale_y_continuous('Time [milliseconds]') # To get axis ticks
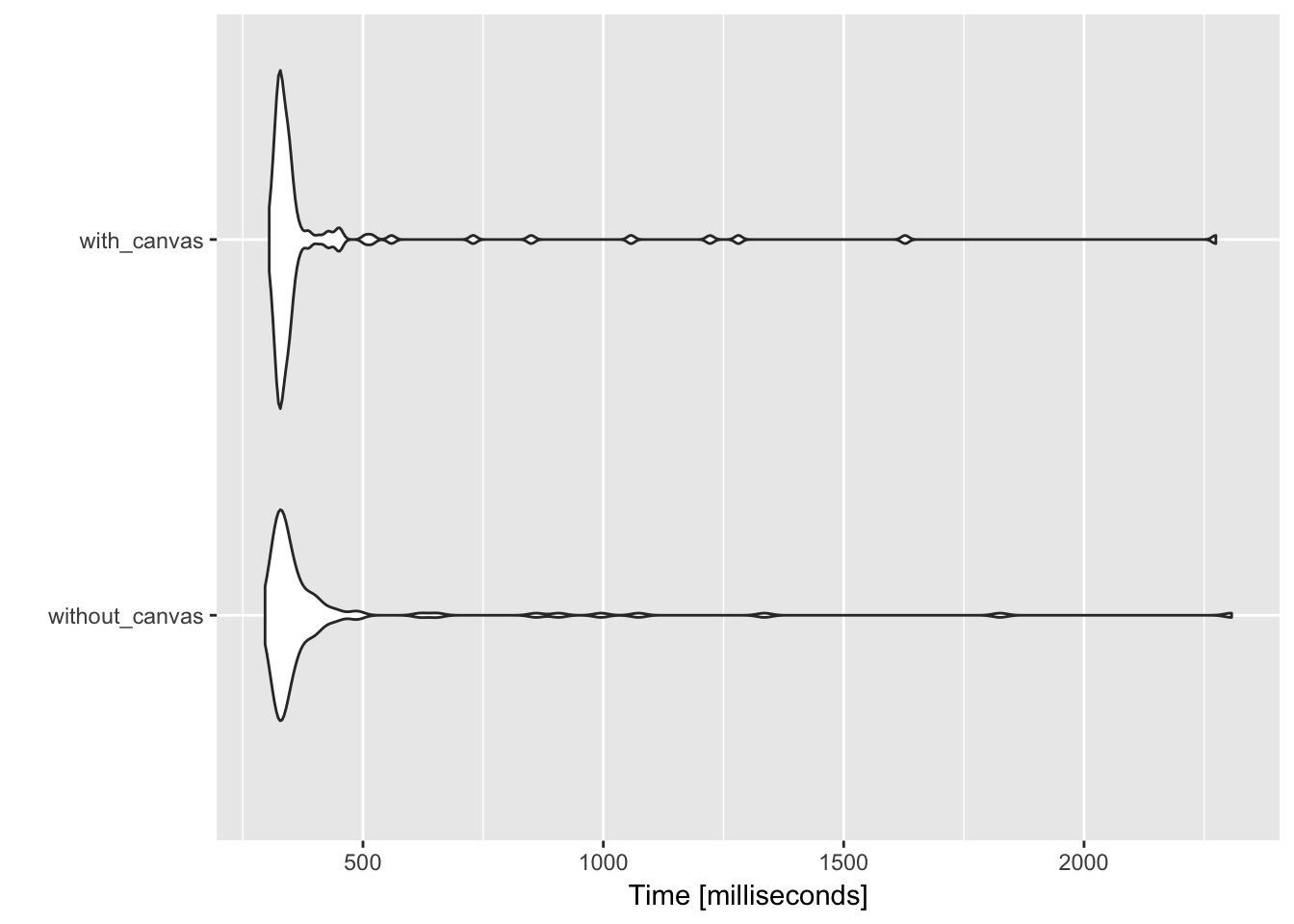
So it appears any time difference is hidden by the actual complexity of rendering the plot. This is sensible as the time scale has now increased considerably and a difference in 1 ms will not be visible.
Strange trivia that I couldn’t fit in anywhere else
Prior to ggplot2 v2 simply plotting the result of ggplot() would result in an error as the plot had no layers to draw. ggplot2 did not get the ability to draw layerless plots in v2, but instead it got an invisible default layer (geom_blank) that gets dropped once new layers are added. This just goes to show the amount of logic going into plot generation in ggplot2 and why it sometimes feels magical…